Intro & Background
ML模型会因为训练和测试时的数据分布不同,导致很多预测错误。将ML模型优化database也面对这个问题。
Active learning
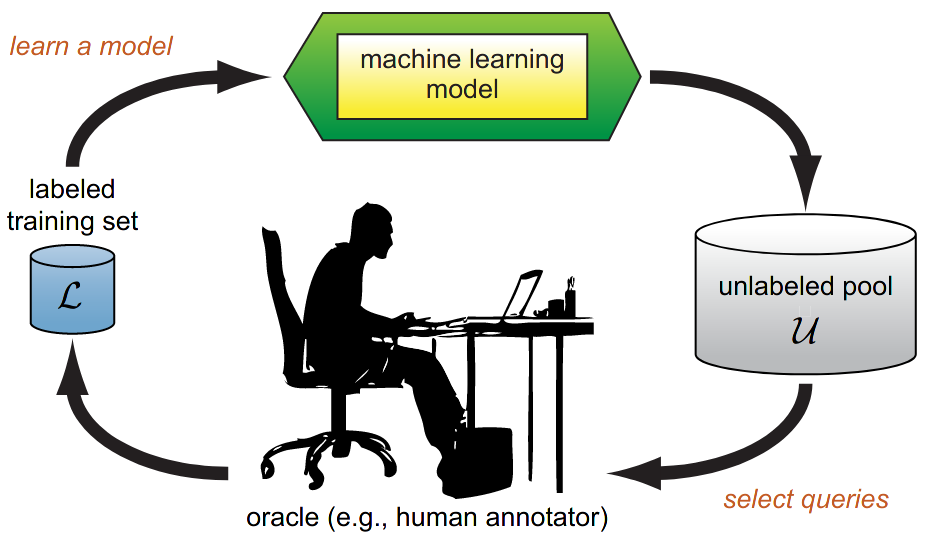
主动学习采用的方法是,可以在unlabled的数据中再选出一些数据,从orcale得到数据的lable,从新的知识中学习。
Execution cost prediction & Plan regression prediction
- ECP是一个回归任务,需要预测执行plan需要的时间。在优化查询中,可以用ECP来寻找最优的plan
- PRP是一个分类任务,给出两个plan,需要找到哪个plan代价更高
Architecture
在这里oracle可以用database的副本执行plan,获取plan的执行时间。因此不同的plan就有不同的cost。
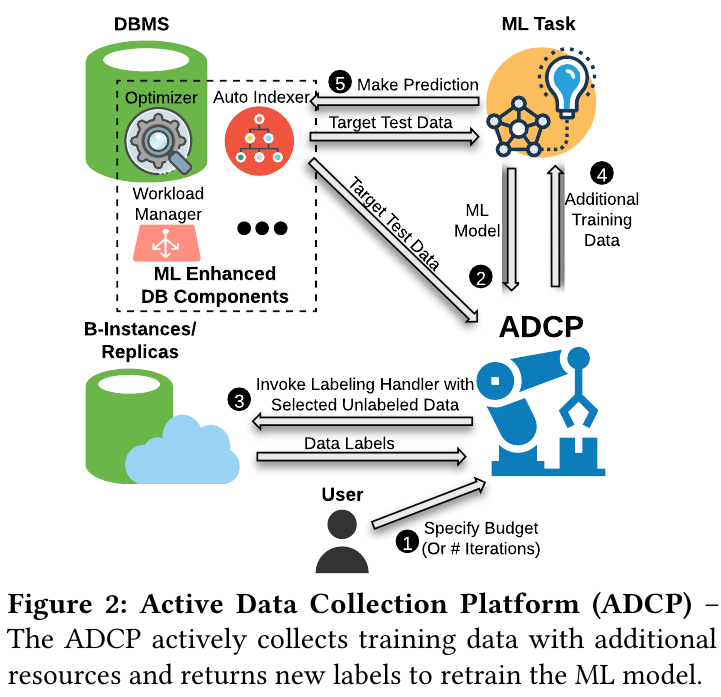
开始,用户指定budget,之后ADCP获取lable数据时会消耗budget。ADCP获取target data,选出unlabeled data给交给副本执行。获得新知识后retrain ML模型,再对target data数据进行预测,这时错误就会降低。
但是新的环境就有新的问题。active learning需要选出要标注的数据,noise会带来一些问题。因此需要综合考虑cost、robust、以及active learning最不确定的unlabel数据。 $$ w_x=\frac{u(x)}{c(x)} $$ $c(x)$表示cost,$u(x)$表示uncertainty,因此x的权重可以理解成“uncertainty per cost”。
同时为了解决noise,转化为概率并加入Gumbel噪音
$$ p(x)=\frac{w_x}{\sum_{x’}w_{x’}} \newline {\rm arg}\ \max\limits_{x} \log p(x)+G_x $$
另外,还需要减少sample时的冗余。

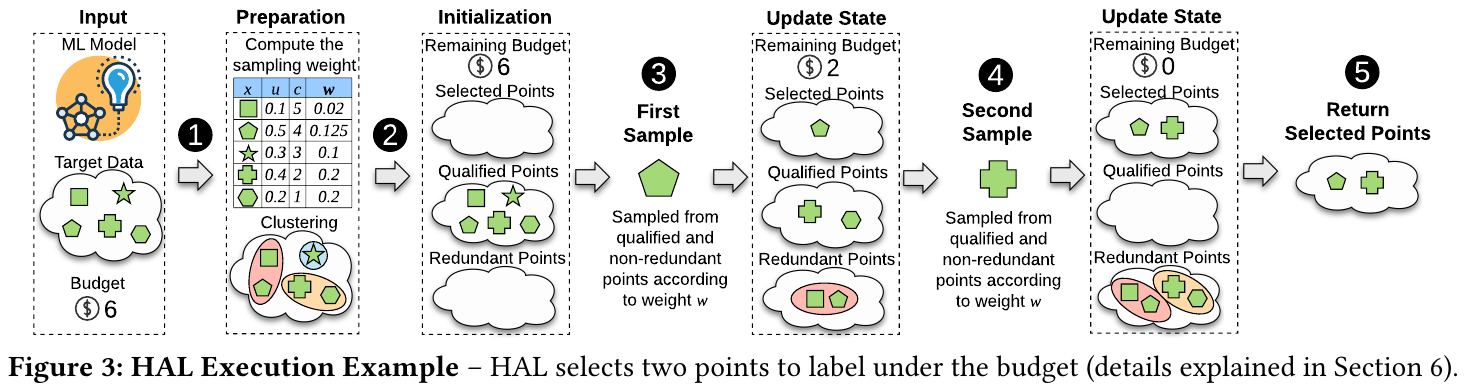
Comparison & Why it works
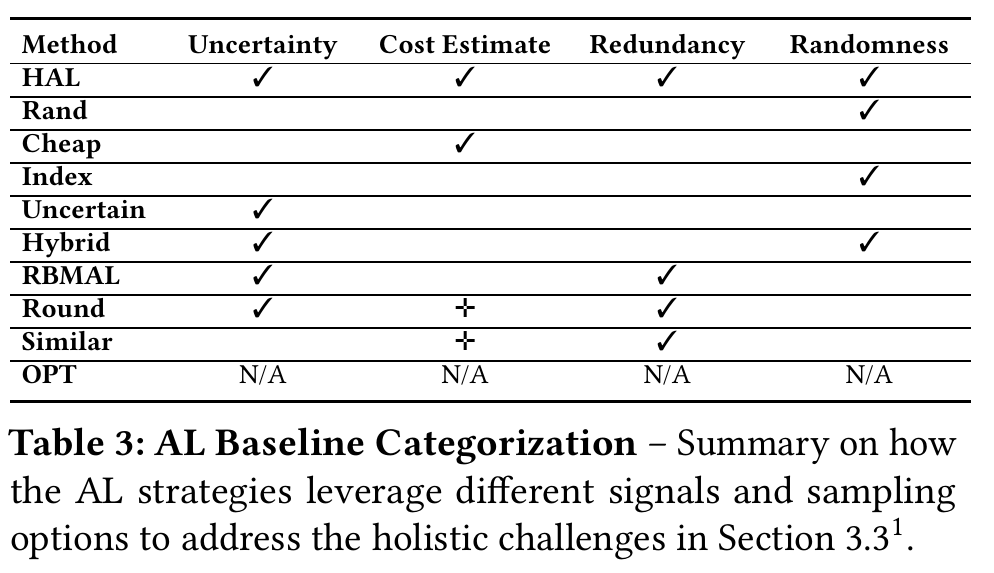
HAL相比于其他AL策略利用了各种不同的特点。感觉这是为什么HAL可以work的一个原因。在实验中,OPT(A crude baseline)直接用cost估计(for PRP),Huber回归(for ECP)得到label不用retrain也不需要额外的label,比其它AL错误要高出很多。
Strategy Properties
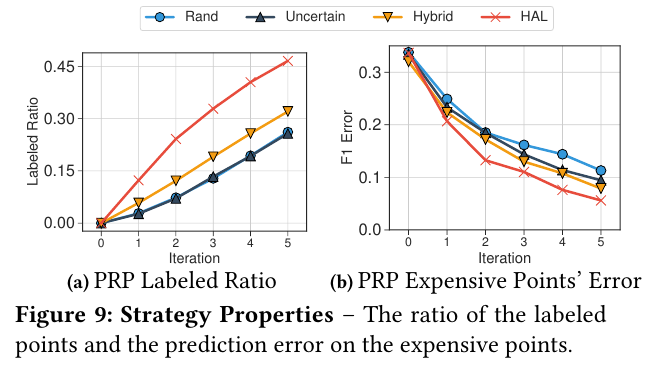
在同样的bugdet下,HAL选出了更多的label,也就是说平均每个label的cost更低(a)。但是,对cost超过平均值的数据,error也更低(b)。