Hi there 👋
Welcome to my blog
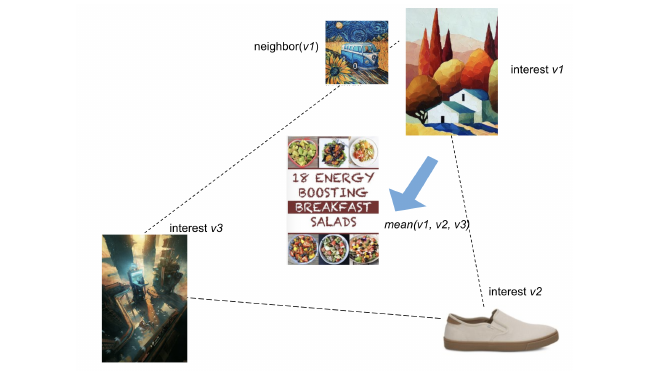
Prelude GNN是最近几年中机器学习较新的一个发展方向,也是学术界和工业界研究的热点话题。相比于node2vec、PageRank,GNN具有更强大的学习能力,能够更好得感知图数据。 GNN的一个经典应用场景是推荐系统。像淘宝这样的电商平台,大量的用户和商品,自然而然地形成了一个复杂异构图,一个直观想法是,可以利用GNN学习用户的兴趣特征,根据用户的历史浏览推荐用户更感兴趣的商品。而且这种方法的推荐质量也更高。 Pinterest Let’s begin with PinSage 1 GNN的开山制作——GCN 2把GNN训练用矩阵乘法来刻画,这样会导致一个问题,每一层每个点都要从他的邻居中读取feature (i.e. 全图训练),导致GNN的复杂度非常高。 后来,一个点在他的部分邻居中读取feature(i.e. 图采样)就可以保证模型的准确度,这样就减低了GNN训练的成本。PinSage也是一个基于采样的GNN算法,是一个早期同时也非常经典的GNN算法。和GraphSage相比,最大的不同点在于用random-walk,采样的子图的质量会好一些。 比如上图就是一个两层的GNN, 在采样完成后我们会得到很多个子图(i.e. mini-batch)并喂给网络训练。每层网络都是如下图所示的图卷积操作,通过聚合特征(e.g. 取平均,求和)再通过一层神经网络得到一下层的输入。将多层图卷积stack到一起就构成了整个GNN,一般只有2-3层。 然而这和推荐系统有什么关系呢?在Pinterest中,有很多pin(类似淘宝的商品,在推荐系统中也称之为item),每个item会包含图片、文本信息,将图片和文本的embedding拼接到一起得到item的初始特征向量。在训练完GNN之后,通过推理得到每个item的嵌入向量,之后推荐系统就可以根据embedding向用户推荐新的item。 Recoommandation System at Pinterest 到推荐系统中,我们会认为每个item的embeddin向量是通过一个黑箱过程(i.e. PinSage),是提前已知的 3。我们的问题是,知道用户点击item历史序列$\mathcal{A}=\{a_1, a_2, …\}$,我们想从$\mathcal{P}=\{p_1, p_2, …\}$中预测下一个用户可能感兴趣的商品。 我们可以想到一些很直观的方法,比如历史的item求平均,还可以按时间给一个权重。但是这样的方法把用户的embedding限制在一个有限的向量里面,效果不是很好,因为一个用户兴趣面是是很广的,对不同种类的商品有不同的喜好。PinnerSage 3 会给用户维护一个不限大小的embedding,不同的种类的喜好都对应到一个嵌入向量。 然而还有另外一个问题——用户的历史序列会很长,计算的复杂度会非常大,影响推荐的系统的延迟。PinnerSage采用的方法是,通过聚类,每个商品都可以用一个类中心来表示。在推荐的时候,根据用户的action再给这些类中心一个重要性评分。最后用最重要的类(e.g. top 3)去预测下一个item。 总结一下PinnerSage的推荐过程分为3步: 用户历史动作序列聚类 得到类中心嵌入向量(Medoid based) 根据time decay计算类的重要度 找哪一个item最合适是一个索引过程,一般会通过cache加速查询。为了兼顾用户的长期兴趣和系统延迟,PinnerSage将任务分成两类,daily和online。在每天PinnerSage都会把用户的历史动作进行聚类的,得到类中心和重要度,这样可以保证和用户兴趣。而在online推荐的时候,只会对用最新的动作在已有的类上refine,降低推荐的延迟。 AliGraph 4 图数据规模的增大给GNN训练带来新的挑战,在工业界,图的规模会非常大,点和边往往是billion量级的。Ali坐拥最大的电商平台之一,大规模图神经网络既有真实的场景,同时也是一个亟须解决的问题。 AliGraph是ali的一个图神经网络框架。从系统的角度来看,AliGraph需要为上层用户提供应有的支撑,使得上层算法和应用开发可以仅仅关注自身的逻辑,而不用担心资源如何分配的问题。 面对超大规模的图,AliGraph通过parition把图分布式存在集群上,解决了存储的问题。同时通过维护cache,尽可能减少partition之间的通讯开销。同时AliGraph还需要实现常见的算子来支持上层GNN应用。AliGraph也进行了开源,GraphLearn 5,同时支持推理和训练任务。 GNN训练基本都是大同小异,而推理任务是部署和落地中主要workload,而且大部分的计算资源也是花在推理上。考虑到真实场景下,图一般是动态(e.g. 新用户的加入),GraphLearn后来增加了Dynamic Graph Service (DGS)来支持动态图的推理任务。 整个系统通过微服务的方式运行,每个模块被拆到subservices,模块之间都通过队列连接起来(e.g. kafka)。 美团广告推荐 6 可以发现在和Pinterest的推荐系统其实在设计上有很多共同点。 美团在推荐任务中有两个观察点:数据样本稀疏,广告投放后点击量非常少;用户兴趣存在时空特点,在不同时间点和地点用户有不同的兴趣点。通过异构图构建、注意力机制等方法解决的推荐不准确的问题。 整个推荐也分成online任务,保证请求低延迟;以及offline任务,用来更新图节点embedding,学习用户的长期兴趣。而整个系统的部署方式和GraphLearn也有一些相似性。 Challenges still exist 在很多业务场景下,图并不是静态不变的而是呈现出一种时间特征,一些点在$t_0$时加入,之后在$t_1$时删除。但是时序图GNN(TGNN)仍然是一个open的问题 7。在近几年GNN的发展中,开放的标准数据集(e.g. OGB 8)有着巨大的贡献,不论是GNN算法还是GNN系统开发,都会将OGB作为数据集和其他baseline比较。然而目前TGNN并没有对应的标准数据集,这样我们很难去比较不同来自不同团队的工作。另一个方面,GNN的收敛性和表达能力是可以被证明的,但是TGNN还是一个相对较新的算法,并没有GNN成熟,缺少基础的理论支撑。 GNN虽然网络层数少,计算资源需求不大,但是图和特征需要占用大量的存储资源,这给GNN部署和落地带来了一些挑战 9。 ...
Unicode丰富了日常使用的字符集, 让我们可以使用一种简单便捷的方式表达各种奇怪的字符, 比如想要在输入一个雪人Snowman, U+2603 ☃ latex作为日常使用的排版工具, 怎么在latex中插入一个unicode? 一般来讲, 应该Ctrl+C, Ctrl+V就可以, 我们来看看下面的代码 \documentclass[utf8]{article} \begin{document} \huge Unicode char \texttt{U+13105} is 𓄅 Unicode char \texttt{U+16E4} is ᛤ Unicode char \texttt{U+25E6} is ◦ \end{document} 然而输出的PDF中并没有包含所有的Unicode字符, 看起来这个问题还存在一定的共性unicode-characters-not-displaying-in-xetex, 而且似乎是个字体问题. Tex Engine使用xelatex 我们来试试更换为FreeMono字体 \documentclass[utf8]{article} \usepackage{fontspec} \setmainfont{FreeMono} \begin{document} \huge Unicode char \texttt{U+13105} is 𓄅 Unicode char \texttt{U+16E4} is ᛤ Unicode char \texttt{U+25E6} is ◦ \end{document} Ha!现在ᛤ已经可以正常显示了, 𓄅却变成了一个奇怪字符. 其实这是因为在FreeMono字体中缺失字符𓄅, 而ᛤ之所以能显示是因为FreeMono包含了这个字符. ...
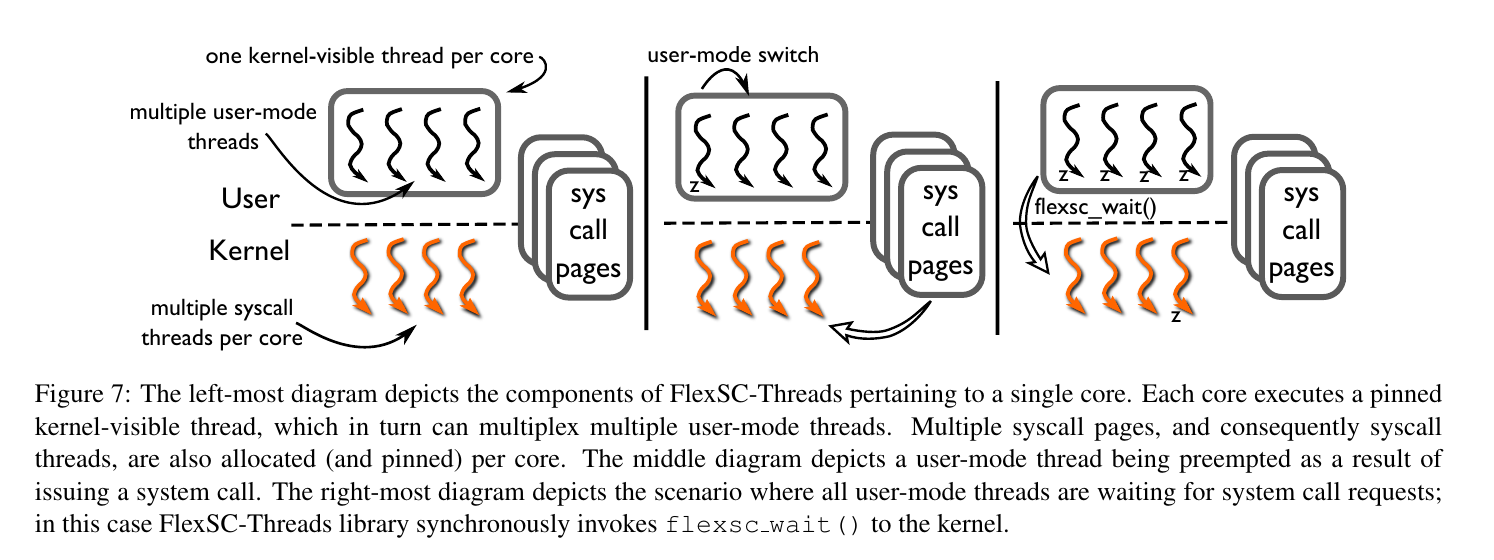
System Call Cost 应用程序通过System Call向kernel请求服务。一般应用程序发起系统调用后,从用户态进入内核态,最后从异常退出,返回用户态。 但是这种同步的系统调用机制可能对应用的性能带来限制: Direct Cost: 在系统调用后,CPU会清空流水线。 Indirect Cost: 程序的局部性以及cache可以提升性能。但是在系统调用后,要在kernel空间执行代码,这就会影响cache性能。而且在kernel处理结束返回用户后,相比与原来的cache,cache受到了污染,带来间接性能损失。 可以看到在系统调用后,IPC(Instructions Per Cycle)降低。 Exception-Less System Call exception-less系统调用,让系统调用异步完成。在user和kernel共享一些syscall pages,用这些syscall page记录当前请求的系统调用。用户发起系统调用后,在syscall pages中添加新的entry后就可以返回。同时,有一些特殊的kernel thread,syscall thread,在syscall pages中找到请求的系统调用,把返回值写在相应的条目。最后用户就通过可以检查syscall pages,拿到返回值。 那这种将invoke和execute解耦的设计怎么做有什么好处呢? 可以推迟执行,把syscall按batch执行,降低mode之间转化的代价,improve temporal locality。 对于多核系统,可以把syscall放在另一个核上执行,这样就可以降低间接代价,improved spatial locality。 Implementation 在实现时,作者添加两个新的系统调用,都采用同步的系统调用机制。 flexsc_register,做一些syscall page的映射,并创建syscall thread,数量等于page中entry的数量。 flexsc_wait,因为这种异步机制,会出现用户需要停下来等待系统调用的完成。 syscall thread的调度,会影响exception-less syscall的性能。对于单核,调用flexsc_wait后,调度syscall thread处理page中每个entry,如果出现阻塞,就用新的syscall thread接着处理一下个entry。多核时,one syscall thread per application and core,这样就带来了并行处理的可能。 FlexSC Threads 但是这样异步方式,可能会让使用变得复杂,而且随着多核的发展,作者就实现了FlexSC-Threads。利用dynamic loading,系统调用时,调用一个wrapper,这样就可以让应用得到free lunch。 维护$M$个user-mod thread,对一个process,每个核上只有一个可以被kernel看见。发起系统调用的线程,在写好entry后,就会被切换执行一下thread。用完ready的user-mode thread,就看看syscall page上有没有完成的。如果还没有ready的,就需要调用下flexsc_wait。 对于这种设计,需要提高并发,来提升性能。highly threaded workloads是FlexSC-Threads的理想环境。 Reference [1] Soares L, Stumm M. FlexSC: Flexible System Call Scheduling with Exception-Less System Calls[C]//Osdi. 2010, 10: 33-46.
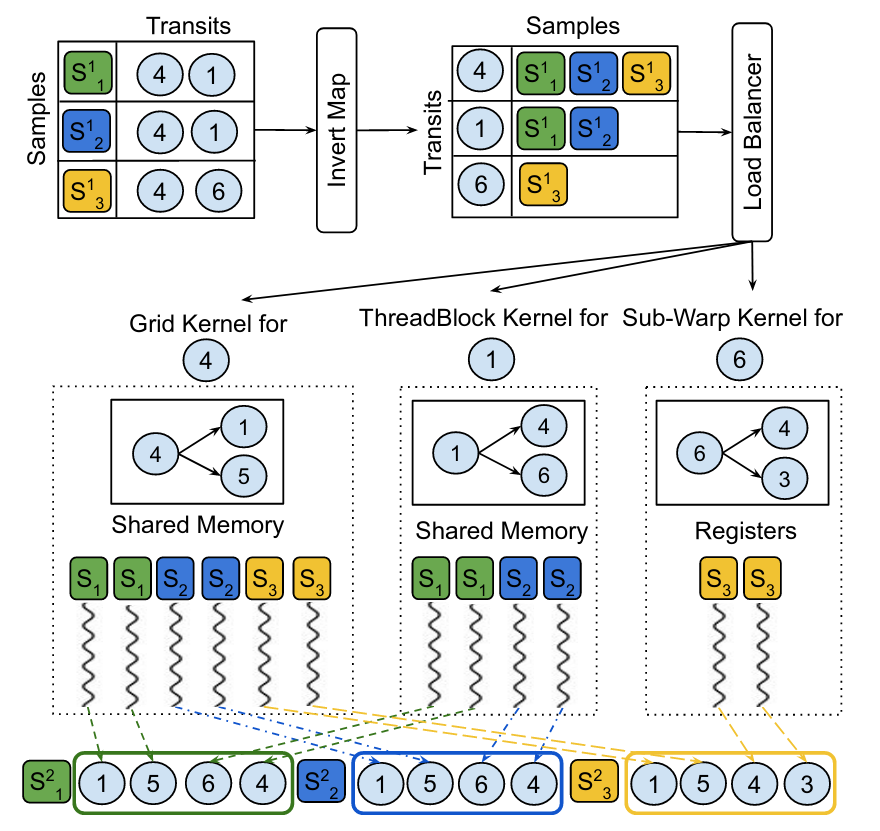
Background 基本各种东西都可以用图来表示,也就促成了GNN的快速发展。然而很多图都有这样的特点,一些节点的度数很高然而大多数节点的度数很低。 训练时要用邻居更新当前节点,不能将整个图全部拿来训练,因此一般采用graph sampling+mini batch,比如,给$n$个节点,每个节点对邻居采样后在进行训练。 然而产生了新的问题,采样在整个训练过程中占了很多时间。 因此,大家也会去想用GPU加速采样,但是naive的方法并不能很好的利用GPU。 “Transit-Parallelism” 作者首先对采样进行了抽象,采样从一节点开始,扩展出新的节点加入sample,再从新的节点扩展$\cdots$,每次遍历邻居扩展新节点的节点,作者把它叫做"transit vertices" 将采样分成两类: Individual Transit Sampling,这个是按节点来的,每个transit节点从邻居中采样一定数量的节点 Collective Transit Sampling,这个是按层来,每一层从所有transit节点的邻居中采样一定数量的节点 CUDA & GPU 一个CUDA程序被划分给很多blocks of threads完成并行,而GPU又由很多StreamingMultiprocessors (SMs)构成,每个block被放到SM上执行 一个block的线程数是有限的,但是相同的大小block可以被组织成grid,于是kernel(a c++ function)就可以用grid里面所有的线程。 $$ thread \xrightarrow[]{array} block \xrightarrow[]{array} grid $$ 众所周知,内存层次结构,GPU当然也有: 前面已经提到了block会在SM上执行,在物理实现时会用到SIMT(Single-Instruction, Multiple-Thread)。multiprocessor用warp(a group of 32 threads)来管理线程。 warp中的线程都从相同的起点开始,但是每个线程都有自己的pc,寄存器状态也可能不一样。而且一个warp的thread执行的指令还是相同的。 如果就是普通的没有控制流的代码,大家就一起执行。那遇到分支怎么办,每个线程可能有不同的路径。这时就会变成串行。warp去执行每个分支路径,不在路径上的thread就等着。这就可能会很影响并行,也就是Branch divergence。 Sample-Parallelism,对于Individual Transit Sampling可以将每一对sample和transit分配$m_i$个线程,每个sample放到一个block里。对于Collective Transit Sampling,需要先把所有的邻居存到global memory里,再采样。 在采样时,邻居多的节点计算的时间就会更久。如果同一个warp里面的两个thread被分给两个邻居数量不同的transit,就会有divergence。而且,图得存在gobal memory,shared memory利用不充分。 但是如果是按transit划分,局部性就会更好,按照工作量需求分配线程数量。是不是有点像倒排索引 :-) 线程组中的线程,他们做的事情更相似,而且工作量也差不多。他们访问的邻居也是同一个transit的,能更好利用share memory。 Sampling Large Graphs NextDoor还可以去对超出GPU memory的图采样。方法有点像mini batch,把图分成不相交的子图,每次对一个子图和和其transit节点采样。 ...
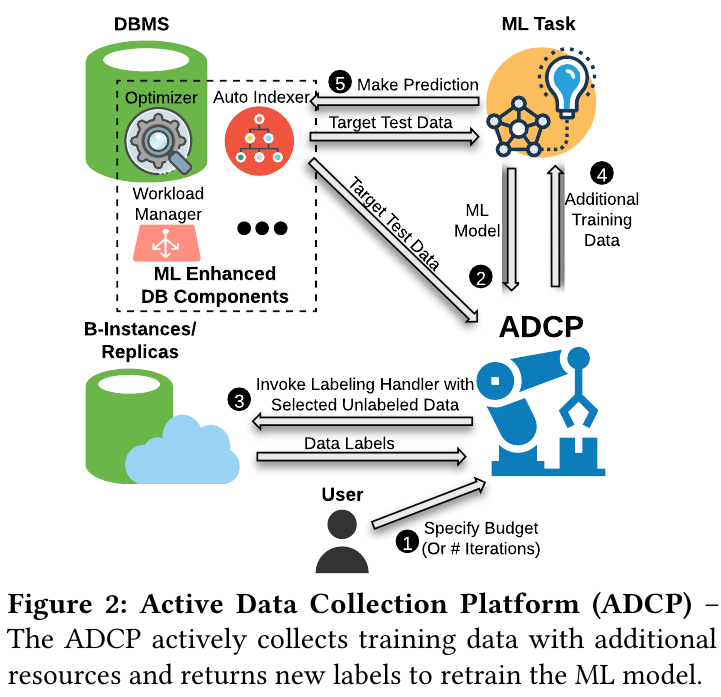
Intro & Background ML模型会因为训练和测试时的数据分布不同,导致很多预测错误。将ML模型优化database也面对这个问题。 Active learning Active leraning 主动学习采用的方法是,可以在unlabled的数据中再选出一些数据,从orcale得到数据的lable,从新的知识中学习。 An illustrative example of pool-based active learning Execution cost prediction & Plan regression prediction ECP是一个回归任务,需要预测执行plan需要的时间。在优化查询中,可以用ECP来寻找最优的plan PRP是一个分类任务,给出两个plan,需要找到哪个plan代价更高 Architecture 在这里oracle可以用database的副本执行plan,获取plan的执行时间。因此不同的plan就有不同的cost。 开始,用户指定budget,之后ADCP获取lable数据时会消耗budget。ADCP获取target data,选出unlabeled data给交给副本执行。获得新知识后retrain ML模型,再对target data数据进行预测,这时错误就会降低。 但是新的环境就有新的问题。active learning需要选出要标注的数据,noise会带来一些问题。因此需要综合考虑cost、robust、以及active learning最不确定的unlabel数据。 $$ w_x=\frac{u(x)}{c(x)} $$ $c(x)$表示cost,$u(x)$表示uncertainty,因此x的权重可以理解成“uncertainty per cost”。 同时为了解决noise,转化为概率并加入Gumbel噪音 $$ p(x)=\frac{w_x}{\sum_{x’}w_{x’}} \newline {\rm arg}\ \max\limits_{x} \log p(x)+G_x $$ 另外,还需要减少sample时的冗余。 Algo & Example Comparison & Why it works HAL相比于其他AL策略利用了各种不同的特点。感觉这是为什么HAL可以work的一个原因。在实验中,OPT(A crude baseline)直接用cost估计(for PRP),Huber回归(for ECP)得到label不用retrain也不需要额外的label,比其它AL错误要高出很多。 ...
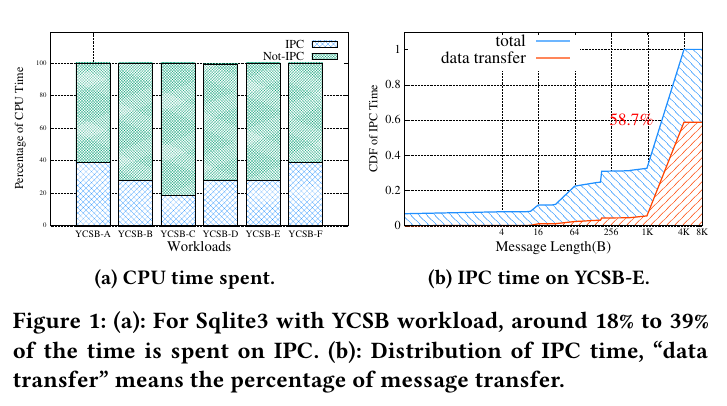
Inter-Process Communication 微内核相比与宏内核,具有更好的扩展性、安全性,也能够更好地容忍错误。但是微内核只保留很基本的功能,很多服务都作为一个用户进程存在,进程之间大量使用IPC传递消息。 另外在宏内核中也会经常使用IPC,如Android Binder。 Optimize synchronous IPC 一般IPC过程需要经过内核,这个过程需要保存用户态状态,当退出内核时还需恢复用户状态。因为每个进程都在自己的虚拟地址空间中,IPC过程还需要切换虚拟地址空间。另外还有一些逻辑需要处理。这些都导致IPC有较高的延迟。 seL4用fastpath降低IPC延迟,消息会被立即发送,让kernel直接切换到server进程避免了调度器,因此可以提升IPC性能。但是也无法避免kernel。 另一方面当传递的消息较大时,IPC一般需要将消息复制到内核,再从内核复制到另一个进程。或者使用共享内存,减少一次复制。 在seL4上测试负载,IPC占用的时间是很多的。 SkyBridge 为了提高IPC性能,SkyBridge想法是IPC不经过kernel,sender可以直接调用receiver的procedure。不进过kernel如何调用receiver呢?似乎需要一个新的模块完成这个功能,SkyBridge利用Intel为虚拟化提供的硬件,EPT(extended page table) 切换,允许在用户态下切换EPT,这样就可以实现在用户态下切换虚拟地址空间。 但是为了利用EPT切换,就需要在增加一个hypervisor。(有可能会影响性能) 在虚拟机中运行的进程,如果要访问内存会经过 GVA(Guest virtual address)➡GPA(Guest physical address)➡HPA(Host physical address) 这样的两级地址转换,经过Guest页表得到GPA,再经过EPT得到HPA 同时SkyBridge中的每个进程都在自己的虚拟空间中,彼此之间相互隔离。如果通过将进程放在同一个虚拟空间,然后用EPT将他们隔离,这样的话当进程数很多的时候就会比较复杂。 从上图可以看到SkyBridge的两个kernel:RootKernel( a tiny hypervisor)和SubKernel(即microkernel)。 首先server在kernel中注册。kernel会吧trapoline-related代码和数据映射到server的虚拟空间,并返回一个ID用来给client调用。client向kernel注册时提供1server ID,kernel同样将代码和数据映射到他的虚拟空间。 Subkernel调用Rootkernel的借口让server和client在EPT level上绑定,kernel会为client和server配置EPT。配置server的EPT时,SkyBridge把client的页表映射到相应server的页表。client调用direct_server_call,切换至server的EPT后使用server的页表翻译后续的地址。trapoline代码安装server的stack,调用handler。 在执行过程中,client的CR3(页表地址)不会发生改变,SkyBridge将client CR3的HPA映射为server C3的HPA,这样就相当于切换到了server的空间。 something else RootKernel & 虚拟化开销,Rootkernel只提供最基本的功能,同时为了降低VM exit,Rootkernel允许像更改CR3的指令不触发VM exit、让外部中断直接到microkernel处理。为了解决EPT violation,Rootkernel用1GB的页,把大部分host物理内存映射到microkernel(除了Rootkernel保留的部分,大概100MB)。这样microkernel访问物理地址时,就不会有EPT iolation。这样不仅降低了处理TLB miss的时间,也降低了TLS miss的次数。 illegal VMFUNC,可能会导致一些安全问题。SkyBrdige的方法是功能相同的指令替换之前的指令。 XPC 但是SkyBridge需要工作在虚拟化环境中,而且当出现调用链的时候(e.g., A$\rightarrow$B$\rightarrow$C)这样出现消息被多次复制的情况。 XPC从两个方面提高IPC性能, 让IPC不经过kernel 不复制传递消息 和SkyBridge一样XPC也属于硬件优化IPC,SkyBridge通过VMFUNC, XPC则通过在新的硬件,XPC engine。XPC engine提供了IPC的基本功能,如capability检查、上下文切换、高效轻量级的消息传递机制(relay-seg)。 XPC engine提供了两个硬件原语:User-level Cross Process Call,Lightweight Message Transfer ...
Codeforces Round #664 https://codeforces.com/contest/1395 A 题意 给四种颜色的球,可以把一个红色一个蓝色一个绿色染成白色,问能不能变成回文串 #include <cstdio> #include <stack> #include <set> #include <cmath> #include <map> #include <time.h> #include <vector> #include <iostream> #include <string> #include <cstring> #include <algorithm> //#include <memory.h> #include <cstdlib> #include <queue> #include <iomanip> #include <cassert> #include <unordered_map> #define P pair<int, int> #define LL long long #define LD long double #define PLL pair<LL, LL> #define mset(a, b) memset(a, b, sizeof(a)) #define rep(i, a, b) for (int i = a; i < b; i++) #define PI acos(-1.0) #define random(x) rand() % x #define debug(x) cout << #x << " " << x << "\n" using namespace std; const int inf = 0x3f3f3f3f; const LL __64inf = 0x3f3f3f3f3f3f3f3f; #ifdef DEBUG const int MAX = 2e3 + 50; #else const int MAX = 2e6 + 500; #endif const int mod = 1e9 + 7; void file_read() { #ifdef DEBUG freopen("in", "r", stdin); // freopen("out", "w", stdout); #endif } int main() { file_read(); int T; LL a, b, c, d; scanf("%d", &T); while (T--) { cin >> a >> b >> c >> d; LL tot = a + b + c + d; if(tot & 1) { int odd = (a & 1) + (b & 1) + (c & 1) + (d & 1); if(odd == 1) { puts("Yes"); continue; } if(a > 0 and b > 0 and c > 0) { a--, b--, c--, d+=3; odd = (a & 1) + (b & 1) + (c & 1) + (d & 1); if(odd == 1) { puts("Yes"); continue; } } puts("No"); continue; } else { int odd = (a & 1) + (b & 1) + (c & 1) + (d & 1); if(odd == 0 ) { puts("Yes"); continue; } if(a > 0 and b > 0 and c > 0 and d > 0) { a--, b--, c--, d += 3; odd = (a & 1) + (b & 1) + (c & 1) + (d & 1); if(odd == 0) { puts("Yes"); continue; } } puts("No"); } } return 0; } B 题意 ...
Gym - 102501D Gnalcats https://codeforces.com/gym/102501/problem/D 题意 给两种栈操作判断是否相等,如果两个操作都fail,也认为相等 Solution 模拟,每个氨基酸一个hash值。通过判断最后栈元素是否对应hash相等,判断操作是否相等 #include <cstdio> #include <stack> #include <set> #include <cmath> #include <map> #include <time.h> #include <vector> #include <iostream> #include <string> #include <cstring> #include <algorithm> //#include <memory.h> #include <cstdlib> #include <queue> #include <iomanip> #include <cassert> #include <unordered_map> #define P pair<int, int> #define LL long long #define LD long double #define PLL pair<LL, LL> #define mset(a, b) memset(a, b, sizeof(a)) #define rep(i, a, b) for (int i = a; i < b; i++) #define PI acos(-1.0) #define random(x) rand() % x #define debug(x) cout << #x << " " << x << "\n" using namespace std; const int inf = 0x3f3f3f3f; const LL __64inf = 0x3f3f3f3f3f3f3f3f; #ifdef DEBUG const int MAX = 2e3 + 50; #else const int MAX = 1e6 + 50; #endif const int mod = 1e9 + 7; void file_read() { #ifdef DEBUG freopen("in", "r", stdin); // freopen("out", "w", stdout); #endif } #define ULL unsigned long long struct DNA { struct Node { int l, r; unsigned LL val; Node(){} Node(int l, int r, unsigned LL val) : l(l), r(r), val(val) {} bool complex() const { return l and r; } }tr[MAX]; stack<int> stk; int tot; int num; DNA() : tot(1), num(1) { for(int i = 1; i <= (int)1e5; i++) { tr[tot] = Node(0, 0, num++); stk.push(tot); tot++; } } ULL hash(int u, int v) { ULL base = 131; return tr[u].val * base + tr[v].val; } bool op_C() { auto u = stk.top(); tr[tot] = tr[u]; stk.push(tot); tot++; return true; } bool op_D() { stk.pop(); return true; } bool op_L() { auto u = stk.top(); stk.pop(); if(!tr[u].complex()) return false; // tr[tot] = tr[tr[u].l]; // stk.push(tot); stk.push(tr[u].l); return true; } bool op_P() { auto u = stk.top(); stk.pop(); auto v = stk.top(); stk.pop(); tr[tot] = Node(u, v, hash(u, v)); stk.push(tot); tot++; return true; } bool op_R() { auto u = stk.top(); stk.pop(); if(!tr[u].complex()) return false; // tr[tot] = tr[tr[u].r]; // stk.push(tot++); stk.push(tr[u].r); return true; } bool op_S() { auto u = stk.top(); stk.pop(); auto v = stk.top(); stk.pop(); stk.push(u); stk.push(v); return true; } bool op_U() { auto u = stk.top(); stk.pop(); if(!tr[u].complex()) return false; stk.push(tr[u].r); stk.push(tr[u].l); return true; } bool op(const string &s) { bool res = true; for(auto c : s) { switch (c) { case 'C':res &= op_C(); break; case 'D':res &= op_D(); break; case 'L':res &= op_L(); break; case 'P':res &= op_P(); break; case 'R':res &= op_R(); break; case 'S':res &= op_S(); break; case 'U':res &= op_U(); break; default: break; } } return res ; } }; DNA A, B; int main() { file_read(); string s, t; cin >> s >> t; A = DNA(); B = DNA(); bool a = A.op(s); bool b = B.op(t); if(a ^ b) { puts("False"); return 0; } if(!a and !b) { puts("True"); return 0; } while(!A.stk.empty() and !B.stk.empty()) { auto u = A.stk.top(); A.stk.pop(); auto v = B.stk.top(); B.stk.pop(); if(A.tr[u].val != B.tr[v].val) { puts("False"); return 0; } } if(!A.stk.empty() || !B.stk.empty()) { puts("False"); return 0; } puts("True"); return 0; } Gym - 102501J https://codeforces.com/gym/102501/problem/J ...
Gym 102460L Largest Quadrilateral Largest Quadrilateral 题意 给$n$个点从中选出四个点,使得面积最大 Solution 首先,肯定是求凸包,要求的点一定在凸包上。 不难联想到凸包对每个边求最大三角形面积的问题,也就是旋转卡壳。 可以将问题转化为,对凸包的每一个对角线$A_iA_j$,求最大面积的两个三角形,$\triangle{A_iA_jP}$, $\triangle{A_iA_jQ}$, 然后就可以枚举对角线,旋转卡壳算最大面积 细节 输出的格式 凸包上应该留下共线的点 #include <cstdio> #include <stack> #include <set> #include <cmath> #include <map> #include <time.h> #include <vector> #include <iostream> #include <string> #include <cstring> #include <algorithm> //#include <memory.h> #include <cstdlib> #include <queue> #include <iomanip> #include <cassert> // #include <unordered_map> #define P pair<int, int> #define LL long long #define LD long double #define PLL pair<LL, LL> #define mset(a, b) memset(a, b, sizeof(a)) #define rep(i, a, b) for (int i = a; i < b; i++) #define PI acos(-1.0) #define random(x) rand() % x #define debug(x) cout << #x << " " << x << "\n" using namespace std; const int inf = 0x3f3f3f3f; const LL __64inf = 0x3f3f3f3f3f3f3f3f; #ifdef DEBUG const int MAX = 2e3 + 50; #else const int MAX = 1e6 + 50; #endif const int mod = 1e9+9; void file_read(){ #ifdef DEBUG freopen("in", "r", stdin); // freopen("out", "w", stdout); #endif } template<typename type> struct Vec { type x, y; Vec() {} Vec(type x, type y) : x(x), y(y) {} friend istream & operator >> (istream &in, Vec &A) { in >> A.x >> A.y; return in; } friend Vec operator - (const Vec &A, const Vec &B) { return Vec(A.x-B.x, A.y-B.y); } friend Vec operator + (const Vec &A, const Vec &B) { return Vec(A.x + B.x, A.y + B.y); } friend type det(const Vec &A, const Vec &B) { return A.x * B.y - A.y * B.x; } friend type dot(const Vec &A, const Vec &B) { return A.x * B.x + A.y * B.y; } friend bool operator < (const Vec &A, const Vec &B) { if(A.x != B.x) return A.x < B.x; return A.y < B.y; } friend type area(const Vec &A, const Vec &B) { return abs(det(A, B)); } friend type operator == (const Vec &A, const Vec &B) { return A.x == B.x and A.y == B.y; } }; template<typename type> vector<Vec<type>> convex_hull(vector<Vec<type>> &pt) { sort(pt.begin(), pt.end()); int n = pt.size(); vector<Vec<type>> res(2*n); int k = 0 ; for(int i = 0; i < n; i++) { while(k > 1 and det(res[k-1]-res[k-2], pt[i]-res[k-1]) < 0) // <=会wa k--; res[k++] = pt[i]; } for(int i = n-2, t = k; i >= 0; i--) { while(k > t and det(res[k-1]-res[k-2], pt[i]-res[k-1]) < 0) // <=会wa k--; res[k++] = pt[i]; } res.resize(k-1); return res; } struct ModI { int i, n; ModI(int n ) : i(0), n(n) { assert(n > 0) ;} ModI(int i, int n) : i(i%n), n(n) { assert(n > 0); } ModI operator ++ ( int ) { ModI row = ModI(i, n); i = (i + 1) % n; return row; } ModI operator + (int x) { ModI res = ModI(i, n); res.i = (res.i + x) % n; return res; } int operator = (int x) { return i = x; } bool operator < (int x) const { return i < x; } bool operator == (const ModI &other) const { return i == other.i; } operator int () { return i; } }; template<typename type> type area(const Vec<type> &A, const Vec<type> &B, const Vec<type> &C) { return area(A-B, A-C); } template<typename type> type rotateCalipers(vector<Vec<type>> pt) { int n = pt.size(); type res = 0; for(int i = 0; i < pt.size(); i++) { ModI p1 = ModI(i+1, n); ModI p2 = ModI(i+3, n); for(ModI j = ModI(i+2, n); j+1 != i; j++) { while(p1+1 != j and area(pt[p1], pt[i], pt[j]) < area(pt[p1+1], pt[i], pt[j])) p1 ++; if(j == p2) p2++; while(p2+1 != i and area(pt[p2], pt[i], pt[j]) < area(pt[p2+1], pt[i], pt[j])) p2 ++; auto cur = area(pt[p1], pt[i], pt[j]) + area(pt[p2], pt[i], pt[j]); res = max(res, cur); } } return res; } void out(LL ans) { if(ans & 1) { printf("%lld.5\n", ans >> 1); } else { printf("%lld\n", ans >> 1); } } int main() { file_read(); int T; scanf("%d", &T); while (T--) { int n; scanf("%d", &n); vector<Vec<LL>> pt(n); for(int i = 0; i < n; i++) cin >> pt[i]; auto ch = convex_hull(pt); if(ch.size() < 3) { printf("0\n"); continue; } if(ch.size() == 3) { LL ans = 0; LL A = area(ch[0], ch[1], ch[2]); for(auto p : pt) { if(p == ch[0] or p == ch[1] or p == ch[2]) continue; auto a = area(p, ch[1], ch[2]); a = min(a, area(p, ch[0], ch[2])); a = min(a, area(p, ch[0], ch[1])); ans = max(ans, A-a); } out(ans); continue; } LL res = rotateCalipers(ch); out(res); } return 0; }
Codeforces Round #663 http://codeforces.com/contest/1391 C 题意 对于一个排列${p_1, p_2, \dots, p_n}$,对于每个数字$p_i$,向前找第一个大于$p_i$的$p_j$,$i$和$j$连一条边,向后同理。求多少种排列生成的图是有环的 Solution 对于$p_i$,如果存在$p_j>p_i(j<i)$, $p_k>p_i(k>i)$,那么就是存在环的 那么对于$\forall i$都不成立时,就没有环 此时就是序列的特点就是,数字$n$左边和右边向两边递减 因此排列数就是$n!-2^{n-1}$ #include <cstdio> #include <stack> #include <set> #include <cmath> #include <map> #include <time.h> #include <vector> #include <iostream> #include <string> #include <cstring> #include <algorithm> #include <cstdlib> #include <queue> #include <iomanip> #include <cassert> #define P pair<int, int> #define LL long long #define LD long double #define PLL pair<LL, LL> #define mset(a, b) memset(a, b, sizeof(a)) #define rep(i, a, b) for (int i = a; i < b; i++) #define PI acos(-1.0) #define random(x) rand() % x #define debug(x) cout << #x << " " << x << "\n" using namespace std; const LL inf = 0x3f3f3f3f3f3f3f3f; #ifdef DEBUG const int MAX = 2e3 + 50; #else const int MAX = 2e6 + 50; #endif const int mod = 1e9+7; void file_read(){ #ifdef DEBUG freopen("in", "r", stdin); #endif } int main(){ file_read(); LL n; scanf("%lld\n", &n); LL fact = 1; for(LL i = 1; i <= n; i++) { fact = fact * i % mod; } LL pow2 = 1; for(int i = 1; i < n; i++) { pow2 = pow2 * 2 % mod; } LL res = (fact - pow2) % mod; if(res < 0) res += mod; printf("%lld\n", res); } D 题意 ...