NextDoor
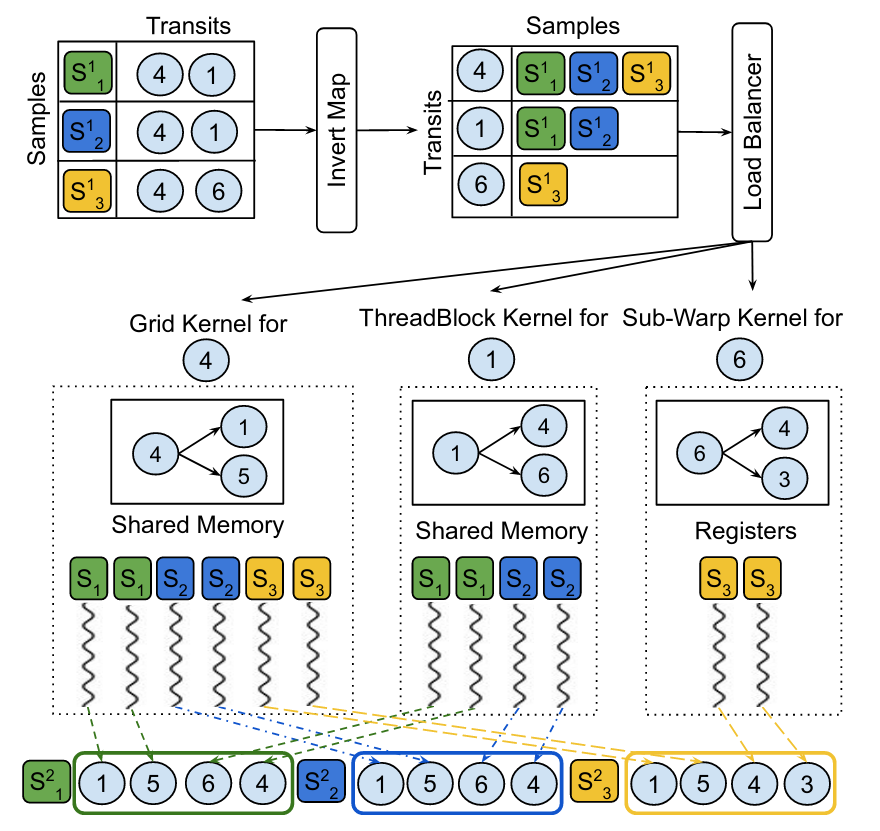
Background 基本各种东西都可以用图来表示,也就促成了GNN的快速发展。然而很多图都有这样的特点,一些节点的度数很高然而大多数节点的度数很低。 训练时要用邻居更新当前节点,不能将整个图全部拿来训练,因此一般采用graph sampling+mini batch,比如,给$n$个节点,每个节点对邻居采样后在进行训练。 然而产生了新的问题,采样在整个训练过程中占了很多时间。 因此,大家也会去想用GPU加速采样,但是naive的方法并不能很好的利用GPU。 “Transit-Parallelism” 作者首先对采样进行了抽象,采样从一节点开始,扩展出新的节点加入sample,再从新的节点扩展$\cdots$,每次遍历邻居扩展新节点的节点,作者把它叫做"transit vertices" 将采样分成两类: Individual Transit Sampling,这个是按节点来的,每个transit节点从邻居中采样一定数量的节点 Collective Transit Sampling,这个是按层来,每一层从所有transit节点的邻居中采样一定数量的节点 CUDA & GPU 一个CUDA程序被划分给很多blocks of threads完成并行,而GPU又由很多StreamingMultiprocessors (SMs)构成,每个block被放到SM上执行 一个block的线程数是有限的,但是相同的大小block可以被组织成grid,于是kernel(a c++ function)就可以用grid里面所有的线程。 $$ thread \xrightarrow[]{array} block \xrightarrow[]{array} grid $$ 众所周知,内存层次结构,GPU当然也有: 前面已经提到了block会在SM上执行,在物理实现时会用到SIMT(Single-Instruction, Multiple-Thread)。multiprocessor用warp(a group of 32 threads)来管理线程。 warp中的线程都从相同的起点开始,但是每个线程都有自己的pc,寄存器状态也可能不一样。而且一个warp的thread执行的指令还是相同的。 如果就是普通的没有控制流的代码,大家就一起执行。那遇到分支怎么办,每个线程可能有不同的路径。这时就会变成串行。warp去执行每个分支路径,不在路径上的thread就等着。这就可能会很影响并行,也就是Branch divergence。 Sample-Parallelism,对于Individual Transit Sampling可以将每一对sample和transit分配$m_i$个线程,每个sample放到一个block里。对于Collective Transit Sampling,需要先把所有的邻居存到global memory里,再采样。 在采样时,邻居多的节点计算的时间就会更久。如果同一个warp里面的两个thread被分给两个邻居数量不同的transit,就会有divergence。而且,图得存在gobal memory,shared memory利用不充分。 但是如果是按transit划分,局部性就会更好,按照工作量需求分配线程数量。是不是有点像倒排索引 :-) 线程组中的线程,他们做的事情更相似,而且工作量也差不多。他们访问的邻居也是同一个transit的,能更好利用share memory。 Sampling Large Graphs NextDoor还可以去对超出GPU memory的图采样。方法有点像mini batch,把图分成不相交的子图,每次对一个子图和和其transit节点采样。 ...